The GWAS Catalog
The GWAS Catalog is a service provided by the EMBL-EBI and NHGRI that offers a manually curated and freely available database of published genome-wide association studies (GWAS). The Catalog website and infrastructure is hosted by the EMBL-EBI.
gwasrapidd facilitates the access to the Catalog via the REST API, allowing you to programmatically retrieve data directly into R.
GWAS Catalog Entities
The Catalog REST API is organized around four core entities:
- studies
- associations
- variants
- traits
gwasrapidd provides four corresponding functions to get each of the
entities: get_studies(), get_associations(), get_variants(), and
get_traits().
Each function maps to an appropriately named S4 classed object: studies, associations, variants, and traits (see Figure 1).

Figure 1: gwasrapidd retrieval functions.
You can use a combination of several search criteria with each retrieval function as shown in Figure 2. For example, if you want to get studies using either one of these two criteria:
- study accession identifier (
study_id) - variant identifier (
variant_id)
You could run the following code:
library(gwasrapidd)
my_studies <- get_studies(study_id = 'GCST000858', variant_id = 'rs12752552')
my_studies@studiesThis command returns all studies that match either 'GCST000858' or
'rs12752552'. This is equivalent to running get_studies separately on each
criteria, and combining the results afterwards:
s1 <- get_studies(study_id = 'GCST000858')
s2 <- get_studies(variant_id = 'rs12752552')
my_studies <- gwasrapidd::union(s1, s2)All four retrieval functions accept the set_operation parameter which defines the way the results obtained with each criterion are combined. The two options for this parameter are 'union' (default) or 'intersection', resulting, respectively, in an OR or AND operation.
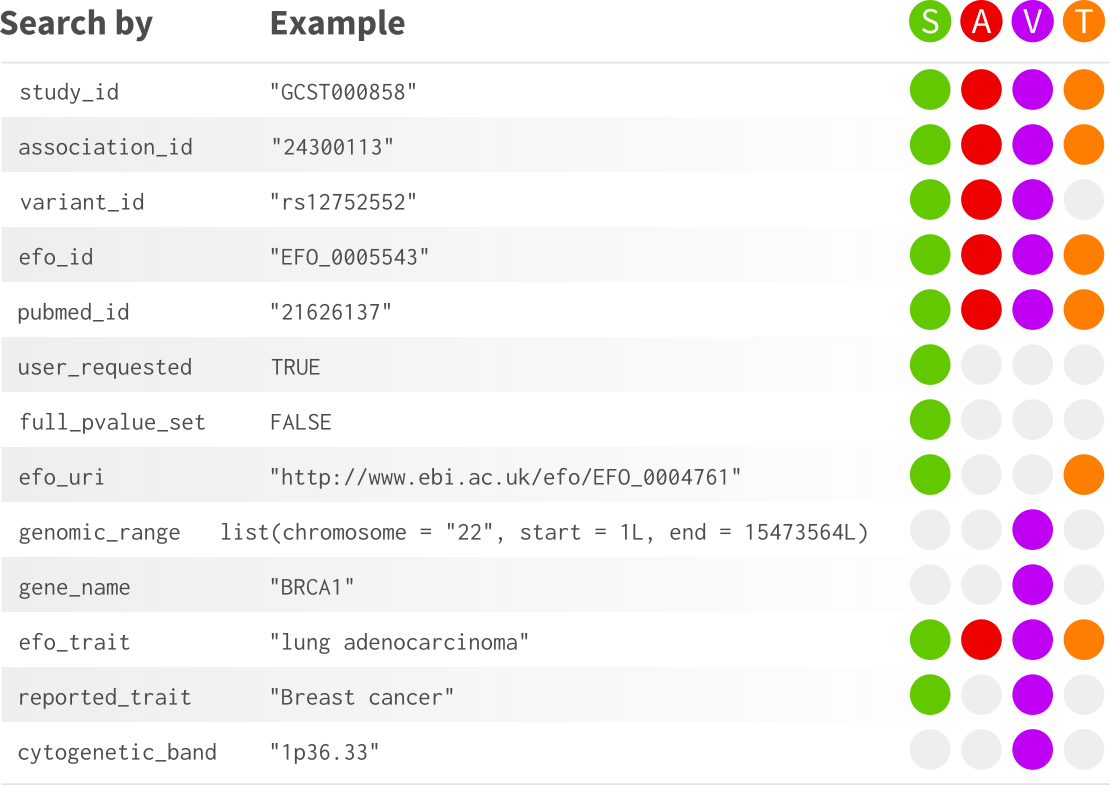
Figure 2: gwasrapidd arguments for retrieval functions. Colors indicate the criteria that can be used for retrieving GWAS Catalog entities: studies (green), associations (red), variants (purple), and traits (orange).
Finding Risk Alleles Associated with Autoimmune Disease
As a first example, take the work by Light et al. (2014). In this work the authors focused on variants that had been previously reported in genome-wide association studies (GWAS) for autoimmune disease.
With gwasrapidd we can interrogate the GWAS Catalog for the study/studies by searching by autoimmune disease (an EFO trait). To do that let’s load gwasrapidd first:
Then query the GWAS Catalog by EFO trait:
my_studies <- get_studies(efo_trait = 'autoimmune disease')We can now check how many GWAS studies we got back:
gwasrapidd::n(my_studies)
#> [1] 9
my_studies@studies$study_id
#> [1] "GCST003097" "GCST011008" "GCST007071" "GCST009873" "GCST011005" "GCST011009" "GCST90029015"
#> [8] "GCST90029016" "GCST90012738"Apparently only 9 studies: GCST003097, GCST011008, GCST007071, GCST009873, GCST011005, GCST011009, GCST90029015, GCST90029016, GCST90012738. Let’s see the associated publication titles:
my_studies@publications$title
#> [1] "Meta-analysis of shared genetic architecture across ten pediatric autoimmune diseases."
#> [2] "Genetic factors underlying the bidirectional relationship between autoimmune and mental disorders - findings from a Danish population-based study."
#> [3] "Leveraging Polygenic Functional Enrichment to Improve GWAS Power."
#> [4] "Meta-analysis of Immunochip data of four autoimmune diseases reveals novel single-disease and cross-phenotype associations."
#> [5] "Genetic factors underlying the bidirectional relationship between autoimmune and mental disorders - findings from a Danish population-based study."
#> [6] "Genetic factors underlying the bidirectional relationship between autoimmune and mental disorders - findings from a Danish population-based study."
#> [7] "Mixed-model association for biobank-scale datasets."
#> [8] "Mixed-model association for biobank-scale datasets."
#> [9] "Clinical laboratory test-wide association scan of polygenic scores identifies biomarkers of complex disease."If you want to further inspect these publications, you can quickly browse the respective PubMed entries:
# This launches your web browser at https://www.ncbi.nlm.nih.gov/pubmed/26301688
open_in_pubmed(my_studies@publications$pubmed_id)Now if we want to know the variants previously associated with autoimmune disease, as used by Light et al. (2014), we need to retrieve statistical association information on these variants, and then filter them based on the same level of significance \(P < 1\times 10^{-6}\) (Light et al. 2014).
So let’s start by getting the associations by study_id:
# You could have also used get_associations(efo_trait = 'autoimmune disease')
my_associations <- get_associations(study_id = my_studies@studies$study_id)Seemingly, there are 182 associations.
gwasrapidd::n(my_associations)
#> [1] 182However, not all variants meet the level of significance, as required by Light et al. (2014):
# Get association ids for which pvalue is less than 1e-6.
dplyr::filter(my_associations@associations, pvalue < 1e-6) %>% # Filter by p-value
tidyr::drop_na(pvalue) %>%
dplyr::pull(association_id) -> association_ids # Extract column association_idHere we subset the my_associations object by a vector of association identifiers (association_ids) into a smaller object, my_associations2:
# Extract associations by association id
my_associations2 <- my_associations[association_ids]
gwasrapidd::n(my_associations2)
#> [1] 180Of the 182 associations found in GWAS Catalog, 180 meet the p-value threshold of \(1\times 10^{-6}\). Here are the variants, and their respective risk allele and risk frequency:
my_associations2@risk_alleles[c('variant_id', 'risk_allele', 'risk_frequency')]
#> # A tibble: 180 × 3
#> variant_id risk_allele risk_frequency
#> <chr> <chr> <dbl>
#> 1 rs11580078 G 0.43
#> 2 rs6679677 A 0.09
#> 3 rs34884278 C 0.3
#> 4 rs6689858 C 0.29
#> 5 rs2075184 T 0.23
#> 6 rs36001488 C 0.48
#> 7 rs4676410 A 0.19
#> 8 rs4625 G 0.31
#> 9 rs62324212 A 0.42
#> 10 rs7725052 C 0.43
#> # … with 170 more rows